Python's range in C++
Exploring loops: Python's range in C++
In spite of what Sean Parent would like (i.e. no raw loops ;-) ), loops are a common control flow in programming.
So common that most languages have more than one loop syntax:
for loop,
while loop,
do while loop...
Given their prevalence, loops might seem uninteresting, but when I decided to look into
creating a range function1 for C++ which would behave like Python's
range object, I learned a thing or two and decided to write them down.
For the impatient, the code I came up with is available on Github. It was inspired by [Anthony William's post](https://www.justsoftwaresolutions.co.uk/cplusplus/ generating_sequences.html) on the subject. I will put the same disclaimer here that Anthony put in his post:
...hopefully people will find this instructive, if not useful.
As he points out, there are more complete alternatives (e.g. the Boost range library) with a probably higher quality of implementation (at the price of bringing the whole of Boost into your project if you do not already depend on it).2
This turned out to be quite a longer blog entry than I anticipated. Consider yourself warned!
Iterating over containers
Out of the C++11 (and beyond) features, range-based for loop is a favorite of mine.
Prior to that being available, if you wanted to iterate over every element of a container, the alternatives were rather verbose.
Amongst others, there is the C style for loop using the iterators that can be retrieved by the begin() and end() functions of the STL
containers:
std::list<double> lst; // ... fill list somehow ...
typedef std::list<double>::iterator lst_iter;
for( lst_iter beg = lst.begin(), end = lst.end(); beg != end; ++beg ) {
double cur = *beg;
// use cur (or use *beg directly everywhere)
}
or the for_each algorithm to which one provides a function object to apply to every element of the container:
std::list<double> lst; // ... fill list somehow ...
struct my_op {
void operator()( double item ) {
// use item
}
};
std::for_each( lst.begin(), lst.end(), my_op() );
Those work, but they have a few drawbacks, amongst which you can find 1) being verbose and 2) not working with built-in arrays3.
Compare that to other languages where the syntax for iterating over a container is more concise and more universally applied, like Python for instance:
a = [ 0, 1, 2, 3, 4 ]
for x in a:
#use x
and you can see a difference, at a minimum in verbosity. With range-based for loops, C++ closes the gap. The syntax, introduced in C++11, is terser and works with both containers and built-in arrays (which is what I show in the example below). Here is what it looks like, which is much closer to the Python for loop:
int ints[] = { 0, 1, 2, 3, 4 };
for( int x : ints ) {
// use x
}
On top of the afore mentioned properties, and probably even more importantly, this construct is much more expressive: it clearly says that you want to use every element of the container. C++ being what it is, of course, the syntax gives you more control than in Python (at the expense of more complexity some would argue): you can specify if you want a copy of each object in the container, a reference to them, or a const reference to them. Thus, all the following declarations (iterating over the same range as the previous example) would be valid:
for( int x : lst ) { /* body */ } // copy
for( int& x : lst ) { /* body */ } // reference
for( int const& x : lst ) { /* body */ } // const reference
That is to say that in C++, you can express that you want to iterate over all the items and whether you intend to modify them or not.
One condition to keep in mind is that in the constructs above, the loop variable type (int in the example above) must be initializable from the type in the container/array you want to iterate over.
This can lead to some errors:
int ints[] = { 0, 1, 2, 3, 4 };
for( long x : ints ) {
// OK, a long can be initialized from an int
}
for( long& x : ints ) {
// Won't compile: long& can't be "initialized from"/"bind to" an int
}
That said, unless you really need to specify the type, it is usually recommended that you use C++11's auto specifier to get type deduction on the loop variable. That would look like this:
int ints[] = { 0, 1, 2, 3, 4 };
for( auto x : ints ) {
// use x
}
which eschews the problems of type mismatch mentioned above. Even with this type deduction, the type decoration can be used so that all those syntaxes are correct and should (usually) have the expected behavior:
for( auto x : lst ) { /* body */ } // copy
for( auto& x : lst ) { /* body */ } // reference
for( auto const& x : lst ) { /* body */ } // const reference
which can have the advantage that if you change the type in the container, you do not have to change the type in the loop. There are some more caveats, especially related to lifetime of temporary objects and accessibility, but the information here is enough in most cases. If you want more information on type deduction in range-based for loops, see this article by Petr Zemek.
One limitation of the C++ syntax compared to Python's is that there is no way to limit the iteration to a sub-range of the container. For this, you still need to use the previous constructs. C++11 made it easier to use these constructs with auto type deduction, but allowing iteration over a portion of the container is still missed, if you ask me, because if it were available, it would mean the same syntax could be used for any iteration over a container. In future versions of the standard, ranges (which are a completely different concept from the function I am writing in what follows... naming things is hard) or view/span types might provide a better alternative, but for now nothing is provided in the standard to iterate over a subrange.
Iterating over indices
Containers (unfortunately or not, depending who you ask), are not the only thing we need to loop over. Iterating over indices can be necessary, and for that, Python has an easy way of creating a temporary "container" that will represent a range of integers. Using this container, the same syntax that was used to iterate over lists can easily be applied to index iteration:
a = [ 0, 1, 2, 3, 4 ]
for x in a:
# use x
for x in range( 5 ):
# use x
As mentioned, the range object created using this syntax will generate the sequence of integers for the loop.
This object can be initialized with a single stop value (as shown), but can also be declared with a start/stop pair or a start/stop/step triplet.
It will go from start to stop (with stop being exclusive, i.e. the interval is[start, stop[) in steps of step. The default value of start is zero and the default value of step is one, which is why you can use the variations with a single parameter or a start/stop pair (which are not strictly speaking overloads, since Python does not allow that).
The parameter step can be negative.
The start value must be smaller than stop when step is positive and greater than stop when step is negative.
range( 10 ) // iterates from 0 to 9
range( 8, 32 ) // iterates from 8 to 31
range( 10, 5, -2 ) // iterates from 10 to 5 in steps of 2
range( 10, 5, 2 ) // does nothing
In C++, neither the language nor its standard library provides such a facility. Thus, to iterate over numbers, one falls back to the C style for loop:
int ints[] = { 0, 1, 2, 3, 4 };
for( auto x : ints ) {
// use x
}
for( int x{0}; x < 5; ++x ) {
// use x
}
This is not actually so bad, but I like the consistency and expressiveness of Python's range object.
In the end, although those reasons might not be the strongest arguments, they still drove me to think about (over-engineer maybe ;-) ) a construct similar to Python's range in C++.
Admittedly, I was also simply a bit curious.
So, I set out to try and see if I could make a function or an object which could work with the range-based for loop much like Python's range object.
The initial "design goals"
Initially, I really wanted the behavior of Python's range object.
I did not want to have to specify the type to iterate over (i.e. short, int, long,
unsigned...).
I wanted to be able to go in both directions, i.e. increment or decrement the counter.
I wanted to be able to specify the step size.
Basically, I wanted to be able to write loops over indices like this:
for( auto idx : range( 6 ) ) { /* body */ }
for( auto idx : range( 2, 7 ) ) { /* body */ }
for( auto idx : range( 38, 13, -3 ) ) { /* body */ }
I also wanted it to be as close to the raw C style loop efficiency as possible, or the same even. If there were a large performance penalty, this would probably be a show stopper: C++'s "zero-cost abstractions" mantra. Actually, I would argue that usually, in C++, even in non performance critical code, a cost in performance has to be greatly outweighed by a gain in expressiveness for a feature/proposal to even be considered, for better or worse.
So, with the following short list of goals:
- Python
rangebehavior,start/stop/step,- increment/decrement,
- no explicit type specification,
- no runtime overhead,
I set out to build a function (or object) in C++. In order to do that, I first had to understand the range-based for loop4.
Writing the code
Understanding range-based for
As defined by the C++17 standard in section 9.5.4 The range-based for statement ([stmt.ranged]), there are three main components to the range-based for construct:
- a range declaration,
- a range initializer,
- a loop statement.
At its simplest, this is expressed like this:
for( for_range_declaration : for_range_initializer ) {
loop_statement
}
The for_range_declaration serves to create the variable that will be used in the loop.
The for_range_initializer is what is executed to get the range (can be as simple as what I would call "identity", i.e. a range can directly be passed in).
The loop_statement is essentially the body of the for loop as with any C style for loop.
The code above will be used by the compiler to generate something similar to the regular iterator loop shown in the [first section]({{< ref "#iterating-over-containers" >}}).
The code looks like this5:
auto&& rng = for_range_initializer;
auto beg = begin( rng );
auto end = end( rng );
for( ; beg != end; beg++ ) {
for_range_declaration = *beg;
loop_statement
}
where the begin and end functions are not necessarily free functions, and can be the equivalent member functions of most STL containers.
Actually, if either a begin or an end member function are found in the range object, the pair of member functions is preferred as specified in the standard.
This unfortunately means that if an unrelated function exists in the class, but has one of those names, the class cannot be used in the range-based for statement even if an appropriate free functions pair is provided. This is true regardless of the access specifier of the function (i.e. a private function with such a name will still prevent the range-based for, even if a valid, non member pair of begin/end functions exists).
I believe this might be changed in the future, but for the C++11 to C++17 versions of the standard, range based for is defined this way.
With the definition above in mind, the requirements to use a range-based for loop can then be summarized as having two related types: first, a range like type that has both a begin and an end function (either member, or discoverable through ADL, i.e. in a related namespace) and second, an iterator like type which can be compared for inequality, incremented and dereferenced, i.e. implements the operator!=, operator++, and operator* functions.
The begin and end functions of the range like type must return objects of the iterator type.
If those criteria are met, then the range-based for loop construct is usable with the range like type.
The requirements can be summed up in code like this:
struct range_iterator {
range_iterator operator++();
bool operator!=( range_iterator const& other );
range_value_type operator*();
}
struct range {
range_iterator begin();
range_iterator end();
}
where range_value_type is the type of the data pointed to by the iterator and contained in the range to iterate over.
Implementing those two types should be enough and so that is what I set out to do.
Thinking of a design
I first looked at Anthony William's code to see how it could be done.
I suggest you take a look at the code (download link) to see the approach he has taken.
I wanted to try and make my own implementation, taking a different path.
In my first attempt, I ended up having to write multiple versions of some of the classes in order to customize the behavior for various types.
For instance, comparing floats with operator== is hardly ever what you want (because of floating point errors), but doing so works perfectly with integral types.
Even with templates, I did not arrive at a customizable design that satisfied me.
Having to repeat myself was not so bad, but I wanted to see if I could avoid breaking the DRY principle.
As I said, a good dose of curiosity. :-)
So I needed to change the behavior depending on what type I iterate over. There are a few alternatives to achieve such behavior in C++. I wanted an alternative that would be compile time based with no runtime overhead. I felt it was necessary to get the efficiency I was aiming for. This meant and abstract base class with virtual functions was not in my solution set. I decided to explore solutions which allowed me to specify the behavior of the class: some kind of "functionality injection". At first, I though of using std::function to hold the "pointers" to the functions to call. That way, I could specify what to use for the three iterator operators when constructing them. The downside of this, from my perspective, is that this will introduce type erasure (and possibly/usually accompanying heap allocations) and indirection, which, if I understand properly, is harder or impossible to optimize for the compiler. I was worried this would not give me the performance I wanted. In thinking and searching for alternatives, I remembered this blog post on inheriting functionalities. This made me think the same technique applied in the blog post CRTP might be the solution I was looking for (did I mention over-engineering?).
Writing some code
Essentially, there are three functionalities that the iterator has to have and so I created three new types that the iterator would inherit from to "consume" the functionality. Applying the CRTP pattern, I parametrized those new types so that they would take the iterator class as a template parameter, and I made the iterator class derive from those types. The implementation ended up as follows:
enum class Direction : uint_fast8_t {
ascending,
descending
};
constexpr auto Ascending = Direction::ascending;
constexpr auto Descending = Direction::descending;
template< typename Iterator, typename Reference >
struct Dereference
{
auto operator*() -> Reference {
return static_cast<Iterator&>(*this).cur_val_;
}
};
template< typename Iterator >
struct Increment
{
auto operator++() -> Iterator& {
auto& self = static_cast<Iterator&>(*this);
( self.direction_ == Ascending ) ? ++(self.cur_val_): --(self.cur_val_);
return static_cast<Iterator&>(*this);
}
};
template< typename Iterator >
struct EqualityComparisons
{
bool operator==( Iterator const& rhs ) const {
return static_cast<Iterator const&>(*this).cur_val_ == rhs.cur_val_;
}
bool operator!=( Iterator const& rhs ) const {
return !(*this == rhs);
}
};
template< typename T >
struct range_iterator :
Dereference< range_iterator<T>, T& >,
Increment< range_iterator<T> >,
EqualityComparisons< range_iterator<T> >
{
using value_type = T;
using reference = T&;
using iterator_category = std::input_iterator_tag;
using pointer = T*;
using difference_type = void;
range_iterator( T val, Direction dir ) :
direction_{ dir }, cur_val_{ val } {
}
private:
Direction direction_;
T cur_val_;
friend Dereference< range_iterator<T>, T& >;
friend Increment< range_iterator<T> >;
friend EqualityComparisons< range_iterator<T> >;
};
template< typename Iterator >
struct Range
{
private:
using value_type = typename Iterator::value_type;
public:
Range( value_type start, value_type stop ) :
direction_{ (start < stop) ? Ascending : Descending },
cur_val_{ start }, end_{ stop } {
}
auto begin() -> Iterator {
return Iterator{ cur_val_, direction_ };
}
auto end() -> Iterator {
return Iterator{ end_, direction_ };
}
private:
Direction direction_;
value_type cur_val_;
value_type end_;
};
A few things worth mentioning.
I have had to make the "operation" classes friends of the iterator class to give them access to the iterator private data.
If I were designing something for the purpose of having client code specialize and extend the behavior, this break in encapsulation might be more of a concern and I might have to go for a different design, since the friend route seems to be the only viable alternative to give the base class access to the derived class data.
But for my current use, it is not something I am worried with.
I also had to explicitly specify the reference type in the Dereference operation.
This is because at the instantiation time of the Dereference template in the inheritance list of the range_iterator, the latter is still an incomplete type and so its typedefs
cannot be used.
Also, for brevity in this blog post, everything is in the global namespace, which is not at all good practice, but in the actual code, I put everything in a estd namespace (for __e__xtended std).
The indentation is also slightly modified for the purpose of the blog post.
In any case, with this code (and the appropriate #includes, again omitted for space), one can iterate over numbers using a range-based for loop like this:
for( auto idx : Range< range_iterator<int> >( 0, 8 ) ) {
// use idx
}
for( auto idx : Range< range_iterator<int> >( 7, -1 ) ) {
// use idx
}
Verbose, shows implementation details, but a start.
This is the beginning of the interface I set out to have.
It allows specifying start and stop (but not the step yet).
It still requires an explicit type specification, which I would like to get rid of.
It will detect whether you want to go in the increasing of decreasing direction, so increment and decrement are covered.
Some might argue the detection is undesired behavior (Python's range will not do this and a step of -1 must be explicitly specified to decrement).
It is debatable I guess, but this is the interface I went with.
As it stands, in the code above, the implementation will accept floating point
types and character types.
This is not allowed by Python's range object (although using the Numpy linspace function, one can get a floating point range).
Unfortunately, the current implementation of the comparison operator is defined in terms of the underlying type's operator==.
As previously mentioned, comparing floats using this operator is not ideal (and might actually never be true in some cases, which would create an infinite loop).
This has been one of the first reasons I have had for specializing in my earlier designs (which are not presented here), and so I will explore it soon, but before I get to that, I will look at performance to see if my design is good enough for me to pursue further.
Evaluating the performance I
Instead of benchmarking the code in the traditional sense of measuring execution time (which is complicated), I decided to look at the assembly generated in Code Explorer (i.e. I godbolted my code !) and see if there was any difference between this looping construct and a traditional C style for loop. My hypothesis is that if the same assembly is generated, then the performance will be the same. I know that fewer instructions is not a guarantee of better performance, but I think it is safe to assume that if the assembly is the same, then the performance will be the same.
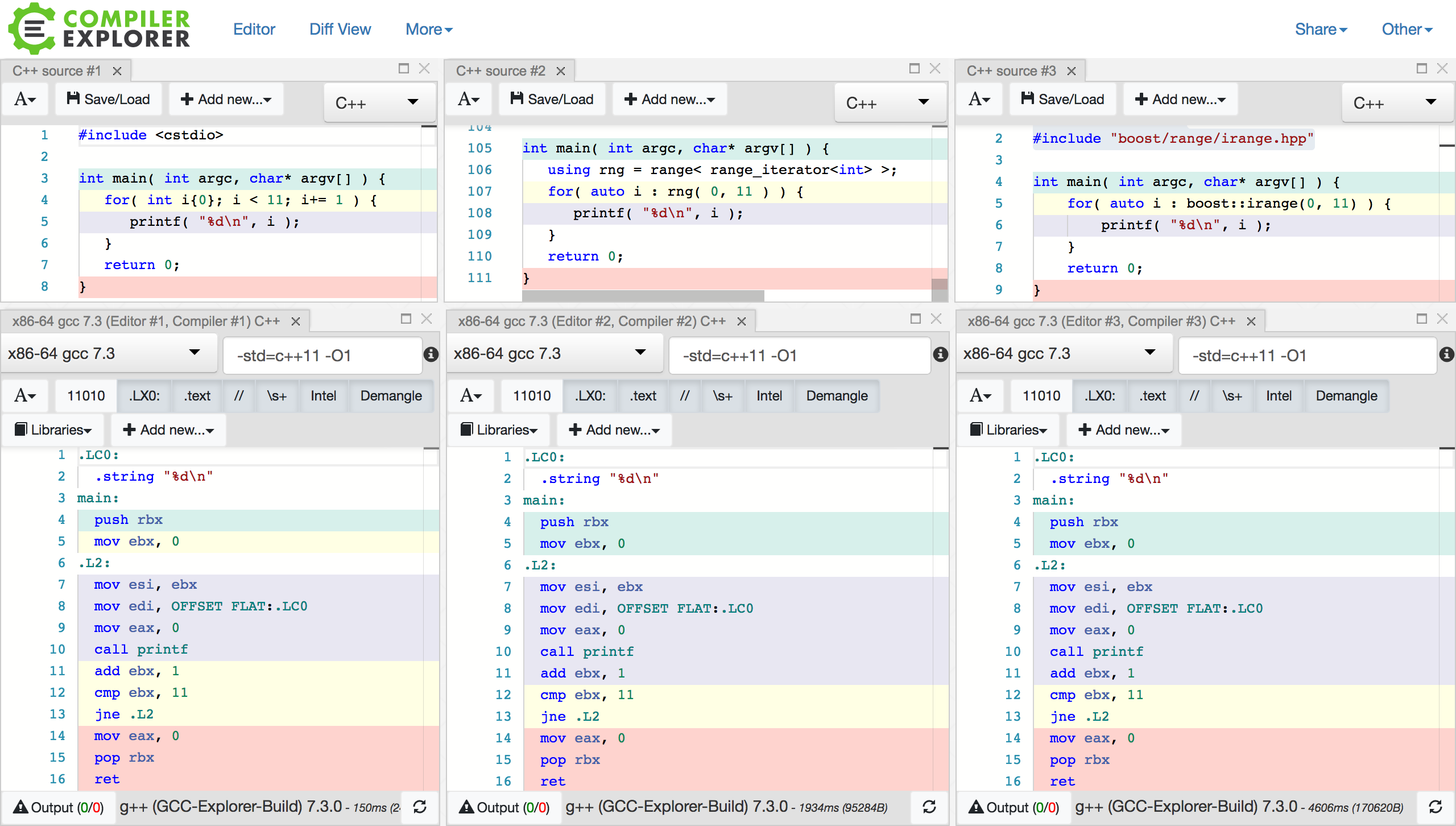
In the above figure, the leftmost editor/compiler pane pair illustrates the C style for loop assembly.
The central pane shows the assembly for the version of the range code as it is in the previous section, and, because compiler explorer provides a version of the Boost libraries, the same loop using boost::irange is displayed in the rightmost pane.
The assembly generated is exactly the same even at a low optimization level (O1).
This means GCC is able to completely see through the abstractions and produce the same output whether this range construct or a hand coded C style for loop is used.
When I saw that, I though it was excellent news, and decided to test with two other commonly used compliers: Clang and MSVC6.
Using Clang, I first got disappointing results: a higher optimization level (O2) was necessary to obtain the same result.
Thinking about why that was, I decided to test if it was related to inlining.
Rewriting the code to use __attribute__((always_inline)) to suggest more aggressive inlining to the compiler, I was able to get Clang to emit the same assembly as a hand written loop at the lower level (O1).
Great.
I then tried with MSVC.
No matter the optimization level or the inlining hints used, for this compiler, there seems to remain a small difference in the assembly generated when using the Range code presented here compared to that generated when using the C style for loop.
This is shown in the following figure:
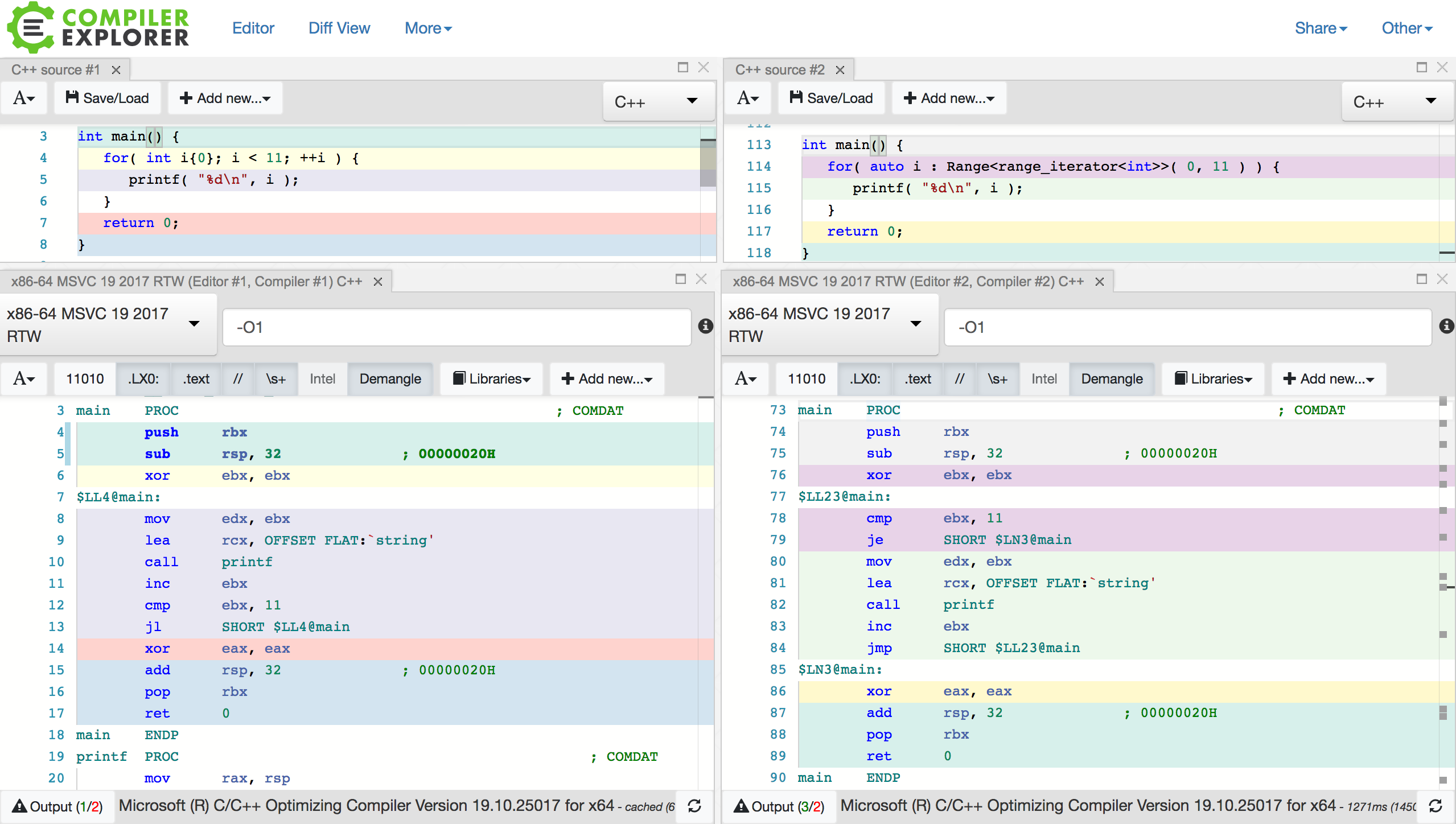
The loops are structured differently.
In the assembly of the hand written loop, there is a single conditional jump instruction back to the beginning of the loop if the loop exit condition is not met, but no other jump instruction.
When the exit condition is met, the program simply continues with the next instruction,
thereby exiting the loop.
On the other hand, the assembly generated by the Range construct contains two jumps: one back to the beginning of the loop when the loop exit condition is not met, and one out of the loop when the condition is met.
The number of comparison instructions (cmp) is the same though and that should be the most significant performance factor.
I imagine for a very short loop (i.e. low number of iterations), the extra jump could be a significant overhead, but for a long loop, I doubt it.
I guess actual profiling would be needed.
Anyhow, at least in that first attempt, performance did not seem to be a big issue (although compile times will go up if that is your metric). This was encouraging to me and motivated me to keep exploring this design.
Dealing with the type specification
The next [design goal]({{< ref "#the-initial-design-goals" >}}) I will be talking about is the explicit type specification, or rather removing the need for it.
The Range object is a class template, and prior to C++17, there is no template parameter argument deduction for class templates.
This means using it directly as in the example above will not allow me to achieve
the "no type specification" goal that I set out for.
However, function templates in C++ always did have template argument deduction and so
they could provide a nicer interface.
Given that the range expression in the range-based for loop does not need to be an object, but can be a function returning an object, it is possible to use a set of function template overloads instead of a Range directly.
With those, the types could be deduced.
Such an overload set can be written as follows:
template< typename T >
auto range( T start, T stop ) -> Range< range_iterator<T> > {
return Range< range_iterator<T> >{ start, stop };
}
template< typename T >
auto range( T stop ) -> Range< range_iterator<T> > {
return range( T{0}, stop );
}
which can be used without a type specification like this:
for( auto i : range( 8 ) ) {
// use i
}
which is now very close to the Python version:
for x in range( 8 ):
# use i
I have tested this on compiler explorer and it produces the same executable as the previous version. So far so good.
Correctly handling floating point ranges
This was not part of the initial [design goals]({{< ref "#the-initial-design-goals" >}}), but dealing with this issue actually helps with the last remaining design goal, so I dealt with it.
In the current version, the main problem with floating point ranges is the
comparison operator.
As it stands, the rest of the code would function properly, but the comparison of begin and end is broken, since it might never yield false and result in an infinite loop (which has happened in testing I should say!).
Said another way, begin might never compare equal to end with the current definition of comparison.
Changing the definition of the operator== to the following unorthodox one would give the proper behavior for floating points:
bool operator==( Iterator const& rhs ) const {
return ( static_cast<Iterator&>(*this).direction_ == Ascending ) ?
( static_cast<Iterator&>(*this).cur_val_ >= rhs.cur_val_ ) :
( static_cast<Iterator&>(*this).cur_val_ <= rhs.cur_val_ );
}
With this definition, for an ascending direction, two iterators are considered equal if the value of the left hand side one is equal or larger than that of the right hand side one.
In the range-based for loop, the right hand side iterator in the comparison is always end(), so for those loops, the comparison as defined above means any iterator with a value of end or more (ascending) are considered equal.
Thus, as soon as the loop iterator's value reaches, or gets past, that of the end iterator, both iterators are considered equal and the loop stops.
This is the desired behavior for the loop, but it is an unusual definition for the iterator if you think of the iterator as the value it holds.
Having an operator with an unusual meaning is generally considered bad practice, and for good reasons. With the previous definition, the result of comparing two iterators can depend on the order of the parameters:
range_iterator<double> a( 42.0, Ascending );
range_iterator<double> b( 48.5, Ascending );
assert( a == b ); // will fire, 42.0 >= 48.5 -> false
assert( b == a ); // will not fire, 48.5 >= 42.0 -> true
assert( ( a == b ) != ( b == a ) ); // will not fire, false != true
which is surprising.
Operators having unusual or inconsistent behavior can be confusing (the C++ Core Guidelines discuss this in their overload section (C.over), more specifically subsections C.160 and C.167).
The problem I am faced with here is that the range-based for loop cannot be customized to use something other than operator!= to compare the two iterators. So whatever behavior I want my iterator to have, it must be in the comparison operator.
That said, for the case at hand, these iterators are part of the implementation of the range function, which is the only part of the library that is considered public.
The only use of the comparison operator should therefore be the one in the range-based for, where the only comparison is between the begin and end iterator pair, which will have the correct behavior.
The iterators are not meant to be used directly and I think the implementation is thus reasonable.
That is debatable for sure, but in any case, in the actual implementation, the function above is defined in the EqualityComparisons class and some template metaprogramming ensures that it applies only to floating point types.
I should warn though that using floating points as a loop counter, either manually or using the range functions here, is not as simple as it seems at first: floating point maths and comparisons are hard and floating point error will be present with the naive loop.
Since the construct proposed here aims only at replacing the naive loop, nothing fancy is done to compensate floating point errors in loops involving floating points, and so I thought a reminder was in order.
Allowing non unit steps
The last goal in my initial list is the non unit step.
For now, I can select start and stop, I allow increment and decrement, I do not need to specify the type, and the performance penalty (with some optimizations enabled) is almost null on the compilers I tested.
The final goal is to allow non unit steps.
In order to do that, I have to:
- store the
stepin the iterator; - adjust the
operator++to advance ofstepunits instead of 1; - adjust the
operator==for integral types; - add an overload to the
rangefunction which takes 3 arguments.
The third item was the easiest to deal with.
The change became necessary, since if the step size is not an exact divisor of the distance between start and stop, the original definition of operator== will never stop the loop, because the loop iterator value will never be exactly the end iterator value, even for integral types.
It turns out that using the same definition of the equality operator as was used to deal with floating point iterators, the problem is solved.
Now, when the value of the loop iterator is above the end iterator value, the loop stops, as desired.
Going back to the first item, the decision I made was to add a template parameter to the range_iterator class which will be of a new enum type Length which tells me whether the range_iterator will have unit length steps or any other length.
Then, I create a specialization for the case where the length is unit and one for when the length is other.
enum class Length : uint_fast8_t {
unit,
other
};
constexpr auto Unit = Length::unit;
constexpr auto Other = Length::other;
template< typename T, Length length >
struct range_iterator;
template< typename T >
struct range_iterator< T, Unit > :
Dereference< range_iterator<T>, T& >,
Increment< range_iterator<T> >,
EqualityComparisons< range_iterator<T> >
{
/* implementation here for Unit length */
private:
Direction direction_;
T cur_val_;
}
template< typename T >
struct range_iterator< T, Other > :
Dereference< range_iterator<T>, T& >,
Increment< range_iterator<T> >,
EqualityComparisons< range_iterator<T> >
{
/* implementation here for Other length */
private:
Direction direction_;
T cur_val_;
T step_;
}
In the case where the length is not one, the step is kept as a data member and available to the operators.
Changing the operator++ was not much more complicated than the change to the comparison operator.
The Increment type is now templated on the length, and, using SFINAE, a different implementation of the operator++ is used depending on whether the length argument is Unit or Other.
auto operator++() -> Iterator< T, length > {
static_cast<Iterator< T, length >&>(*this).cur_val_ +=
static_cast<Iterator< T, length >&>(*this).step_;
}
The only remaining task is to add an overload of the range function.
This overload will take one more parameter (the step) and return a range parametrized
with a different iterator type.
template< typename T, typename U >
auto range( T start, T stop, U step ) -> detail::range< T > {
return detail::range< T >{ start, stop, step };
}
It should be noted that the start/stop and the step parameters can have different types.
This is necessary for someone to be able to call the function like this:
for( auto i : range( 13u, 0u, -3 ) ) {}
If all three parameters were of the same type, then the user would have to manually convert one way or the other, which is not a nice interface.
What is done in the implementation is a cast inside the constructor of the Range object to the iterator type.
Unfortunately, this opens the door to quite a few conversion problems.
If you go from signed to unsigned, the behavior is correct and portable.
If you go from unsigned to signed, the behavior is implementation defined, but should mostly work.
Anyhow, with all of this in place, all my goals are achieved!
Mixed types, logic checking...
As I said, the code above is close to the one I ended up with, but not exactly the same. You can go on Github to find my range function implementation. There are more things one could do with it (or do differently).
One thing that could be done is allow for mixed types to be used for specifying the bounds and not only the step (see previous section). That is actually what prompted my two previous posts about [integer representations]({{< ref "integer_representations" >}}) and [usual conversions in arithmetic]({{< ref "usual_conversions" >}}). I am not illustrating the code here, since it would make this already long post even longer, but it can be done. It does bring up some interesting questions though such as which type to return when two types are used. I am still uncertain what a good answer is. As far as I can tell, Boost range has decided to simply not allow that. This is not unreasonable. That said, the use case I see for allowing mixed types bounds specification is the following:
std::vector< int > v{ 0, 2, 4, 6, 8, 10, 12 };
for( auto idx : range( 3, v.size() ) ) {
// do something with the items 3 to size of vector v
}
Since the standard library has made the choice of having size of containers be unsigned, without mixed bound types, this would not work without asking the user to write 3u as the first index or cast the .size() call result.
Another thing, you will see in the code is some consistency checks.
For instance, if start > stop while step > 0, there is likely a problem (unless you
allow overflowing loops, which could be done).
There are some parts of the code which, with hindsight, seem superfluous.
For instance, there is no difference in the dereferencing behavior in any of the code here, so it would be simpler to leave it in the range_iterator implementation.
It would not be DRY (repeated in two classes), but the complexity introduced might not be worth it. As with any code, I think it can be bikeshedded debated forever. :-)
Anyhow, I hope you have enjoyed reading this post. Writing it certainly made me clarify the concepts involved in range-based for loops in C++ and yielded a construct I can use to loop over indices with a nice pythonish syntax. It is what I initially wanted, so for me at least, mission accomplished!
Acknowledments
I would like to thank Gabriel Aubut-Lussier for taking the time to read this post before I published it and making constructive comments on the content. The writing is better for it.
Notes
[1] The work here will probably be made completely useless by the range proposal when it gets in the standard. On top of that, such a function already exists in Boost. The links were valid at the time of writing. The link to the range proposal is actually to a draft version of the proposal, which might differ from what actually ends up in the standard. ↩︎
[2] Link pointed to most recent release on the date of writing. Might not work on future dates. ↩︎
[3] Edit 2018-08-16: Turns out even in C++98, it works for built-in
arrays, albeit not with the std::begin() and std::end() free functions given
they were introduced in C++11.
You can simply pass the array "bounds" (i.e. the array variable and the array variable plus the length) to the standard algorithm (tested with std::sort) and it works.
You learn every day! ↩︎
[4] At first, like most I would think, I actually first asked a search engine and that is how I found Anthony's post on the subject. This was a great starting point. ↩︎
[5] Adapted from the C++17 standard draft. ↩︎
[6] In the course of writing this article, I realized that a version of the Intel compiler was also available on Compiler Explorer and thus decided to look at the assembly generated with this compiler.
It turns out it takes optimization level 3 for the code to give the same result as the hand-coded loop with this compiler.
Depending on whether or not you can use this optimization level, the performance of the Range presented here might not be very good with this compiler. ↩︎